Home Lab GPU Server Build

Specification Sheet
| Component | Model | Number | Price |
|---|---|---|---|
| MB | AsRock EPYC-D8 | 1 | ¥1100 CNY / ~$150 USD |
| CPU | AMD EPYC-7642 (48C 96T) | 1 | ¥2900 CNY / ~$400 USD |
| RAM | Samsung-32GB-DDR4-RECC-2Rx4-2666V | 8 | ¥1600 CNY / ~ $220 USD |
| GPU | Gigabyte-NVIDIA-2080Ti-22GB-300A | 4 | ¥10000 CNY / ~ $1360 USD |
| Case | BC1 V2 | 1 | ¥1100 CNY / ~ $150 USD |
| PSU | EVGA-1600-T2 | 1 | ¥800 CNY / ~ $110 USD |
| Disk | Kioxia-RC20-NVME-SSD (2TB) | 2 | ¥1300 CNY / ~ $180 USD |
| NAS | QNAP-TVS-951X - 32TB (RAID-5) | 1 | / |
| Total | ¥18,800 CNY / ~ $2570 USD |
*Currency conversion rate: 1USD = 7.33CNY
*This is a note for novice server builders like me. Please help to point out any mistakes. Thanks! ![]()
GPU
I started choosing components for this build after I found the trend of upgrading the 2080Ti VRAM to 22GB for AI image generation with Stable Diffusion. I chose the Gigabyte 2080Ti Turbo Edition (the power connectors are located at the rear) which has TU102-300A-K1-A1 and 13+3 power phase.
A comparison of turbo edition 2080Ti from different brands can be found in this video.
Theoretical Performance
| 2080Ti-22GB | 4090 | 2080Ti x 4 (This Build) | |
|---|---|---|---|
| Pixel Rate | 136.0 GPixel/s | 443.5 GPixel/s | 544 GPixel/s |
| Texture Rate | 420.2 GTexel/s | 1,290 GTexel/s | 1680.8 GTexel/s |
| FP16 (half) | 26.90 TFLOPS | 82.58 TFLOPS | 107.6 TFLOPS |
| FP32 (float) | 13.45 TFLOPS | 82.58 TFLOPS | 53.8 TFLOPS |
| FP64 (double) | 420.2 GFLOPS | 1,290 GFLOPS | 1680.8 GFLOPS |
| VRAM | GDDR6-22GB | GDDR6X-24GB | GDDR6-88GB |
| Power Consumption | 250W | 450W | 1000W |
| Price | ¥2500 / ~ $340 | ¥13000 / ~ $1770 | ¥10000 / ~ $1360 |
Compared with a single 4090, this build has
- 130.30% FP16 Performance

- 366.67% VRAM size
- 76.92% Price
- 65.15% FP32 Performance

- 222.22% Power Consumption
A NOT Too Difficult Choice
My major reasons for choosing 2080Ti x 4 over 4090 x1 are as follows:
- The FP32 performance in this build has a huge drop, but networks rarely need full FP32 accuracy. Instead, the bottleneck is usually the VRAM size when training large networks.
- I want and like the 88GB VRAM in this build.

- Training with lower precision is still the trend and lots of interesting research is going on in this field.
- Federated learning is one of my research interests. Having multiple GPUs can help me set up a virtual training/benching environment in one machine.
- Last but not least, it’s cheaper.
Some major time stamps
- In 2018, NVIDIA released an extension for PyTorch called Apex, which contained Automatic Mixed Precision (AMP).
In 2020, AMP became a core function torch.cuda.amp in PyTorch since version 1.6.
- In 2023, the latest NVIDIA H100 even added support for FP8. NVIDIA Hopper: H100 And FP8 Support (lambdalabs).
Motherboard and CPU
Due to the budget, I wanted to use a set of retired (but not too old) server motherboards and CPUs.
Motherboard
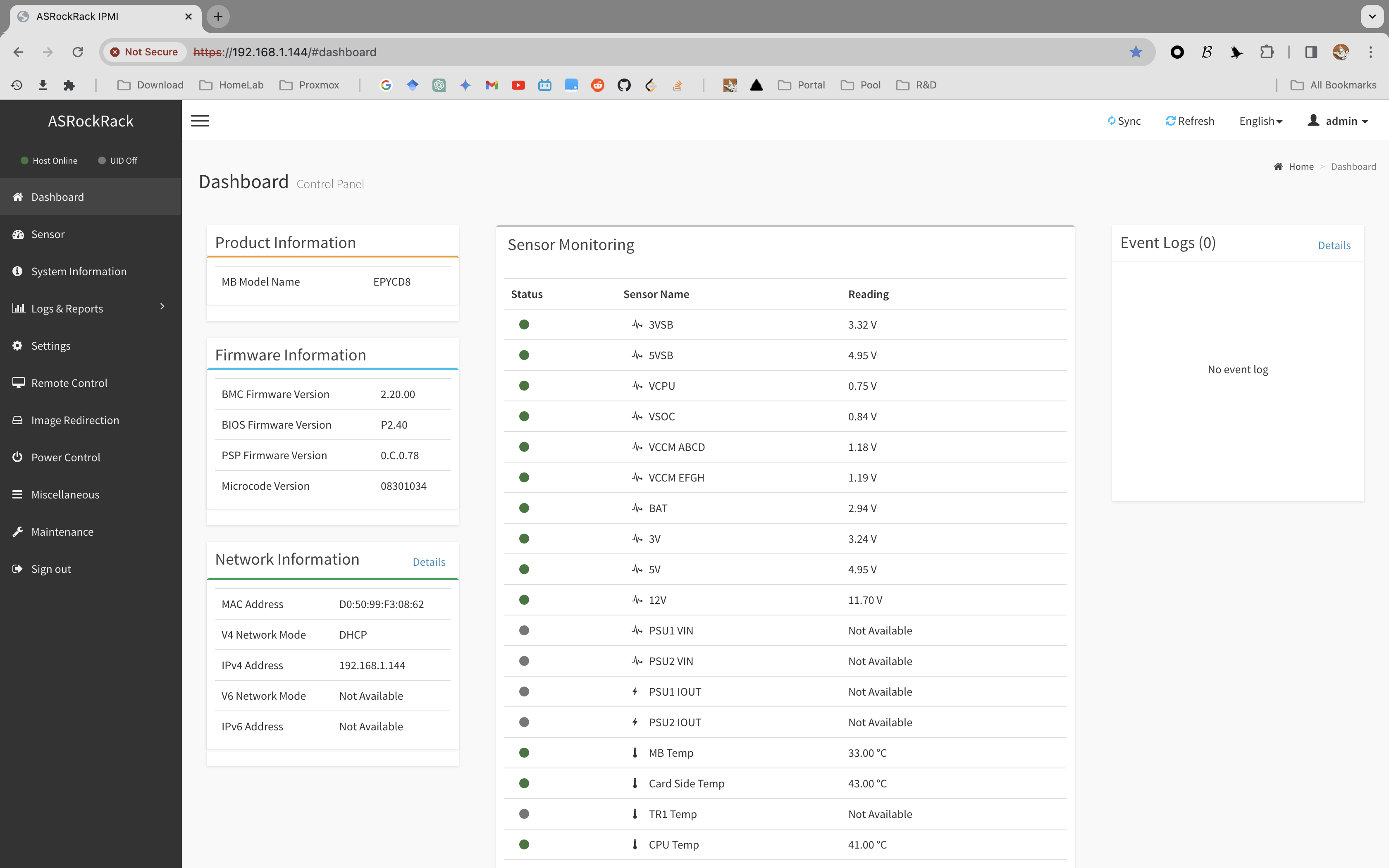
I decided to go with the server motherboard because server motherboards have some really interesting features for a novice server builder like me. The most useful one is probably the Intelligent Platform Management Interface (IPMI), which allows you to remotely manage your server (including powering on and off).
To have [PCI-e x 16] x 4 or more, you would typically want to search for workstation/server motherboards. For the motherboard, I prioritized:
[PCI-e x 16] x4 > CPU Cores = RAM Size > NVME Disk Slotes > SATA/SAS Ports = 10Gb Ethernet
Choosing a motherboard that can support 4 x GPU was a little different from my previous experience with building a gaming PC so I’d like to briefly show my research results.
Here is the list of server motherboards that I’ve compared:
.jpg) EPYC-D8
EPYC-D8

 H12SSL-i
H12SSL-i
Eventually, I chose the AsRock EPYC-D8 because I spend more money on my CPU.
Compared with other components, CPUs are typically much more durable. Spending more money on CPUs seems to be a good choice.
The major downside of choosing this server is it lacks 10Gb ethernet connectors and I can’t attach a 10Gb ethernet card to it either when using it as a 4 x GPU server. If you have more budget and need a 10Gb LAN, consider choosing Gigabyte MZ01-CE0 which has dual 10Gb/s BASE-T ethernet connectors.
CPU
For the CPU, I prioritized CPU Max Boost Clock > CPU Cores. I considered the motherboard and the CPU budget as a whole and ended up with EPYC-7642.
AMD EPYC Naming Scheme
| EPYC 9654P | |||
|---|---|---|---|
| EPYC | Product Family | EPYC EPYC Embedded |
|
| 9 | Product Series | 3xxx 7xxx 9xxx |
Embedded SOC High-performance server CPU/SOC (Zen 1~3) High-performance server CPU/SOC (Zen 4) |
| 65 | Product Model | Fx/xF Hx |
Frequency optimized HPC-optimized |
| 4 | Generation | 1st gen 2nd gen 3rd gen 4th gen |
7001 Naples series, Zen microarchitecture 7002 Rome series, Zen 2 microarchitecture 7003 Milan series, Zen 3 microarchitecture 9004 Genoa series, Zen 4 microarchitecture |
| P | Feature Modifier | (none) P |
1P, 2P 1P (single socket) only |
Based on the naming scheme, EPYC-7642 is the 2nd generation high-performance server CPU/SOC that belongs to the Rome series with Zen 2 microarchitecture and it can be used in motherboards with dual sockets.
RAM and Disk
RAM
While building a gaming PC, using RAM of different sizes/brands/speeds might work (not recommended though). But it’s another story for building a server. It’s worth learning something about Memory Rank.
A memory rank is a data block that is created using some/all of the memory chips on a memory module, which is 64 bits wide (or 64+8=72 bits for ECC). Depending on how a memory module is engineered, it may have one, two, or four blocks of 64-bit (72-bit for ECC) wide data blocks. Those configurations are referred to as single-rank (1Rx4), dual-rank(2Rx4), and quad-rank(2Rx8).
The x4 and x8 refer to the number of banks on the memory component or chip. It is this number, not the number of individual memory chips on a PCB, that determines the rank of the finished module. The drawback with higher-ranked modules is that servers sometimes have a limit on how many ranks they can address.
Memory modules are typically very durable and used server memory modules are fairly cheap. So I got 256GB RAM for my server build.
PSU
There is an important note! I almost made the mistake of using modular cables for Corsair-SF-600 on EVGA-1600-T2. If you bought a used PSU with cables missing, make sure you bought the right cables!!!
So far, modular cables have NO industry standards! Modular cables are typically NOT compatible between different brands!
For PSU recommendation, check this out PSU Tier List rev. 17.0g ![]()
Case
The case is a little expensive, but the anodized aluminum with titanium color gives it a premium outlook. It also has a durable design which makes it an expensive good deal.

Operating System
As for now, I intend to use this build as an All-In-One server for my home lab. After doing some research, Proxmox is a perfect solution for me.
A GitHub repository for self-hosted applications: Awesome-Self-hosted ![]()
Download
Proxmox ![]() Rufus
Rufus ![]() VirtIO Driver for Windows
VirtIO Driver for Windows ![]()
Network Configuration
Bonding a.k.a. Link Aggregation
Understanding and Configuring Linux Network Interfaces
Network Configuration (Proxmox Documentation)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# /etc/network/interfaces
auto lo
iface lo inet loopback
iface enp66s0f0 inet manual
iface enp66s0f1 inet manual
auto bond0
iface bond0 inet static
bond-slaves enp66s0f0 enp66s0f1
bond-miimon 100
bond-mode balance-alb
bond-xmit-hash-policy layer2+3
auto vmbr0
iface vmbr0 inet dhcp
address 192.168.1.252/24
gateway 192.168.1.1
bridge-ports bond0
bridge-stp off
bridge-fd 0
# The IP address is given to the bridge, not the bond
bond-mode
- Round-robin (balance-rr): Transmit network packets in sequential order from the first available network interface (NIC) slave through the last. This mode provides load balancing and fault tolerance.
- Active-backup (active-backup): Only one NIC slave in the bond is active. A different slave becomes active if, and only if, the active slave fails. The single logical bonded interface’s MAC address is externally visible on only one NIC (port) to avoid distortion in the network switch. This mode provides fault tolerance.
- XOR (balance-xor): Transmit network packets based on [(source MAC address XOR’d with destination MAC address) modulo NIC slave count]. This selects the same NIC slave for each destination MAC address. This mode provides load balancing and fault tolerance.
- Broadcast (broadcast): Transmit network packets on all slave network interfaces. This mode provides fault tolerance.
- IEEE 802.3ad Dynamic link aggregation (802.3ad)(LACP): Creates aggregation groups that share the same speed and duplex settings. Utilizes all slave network interfaces in the active aggregator group according to the 802.3ad specification.
- Adaptive transmit load balancing (balance-tlb): Linux bonding driver mode that does not require any special network-switch support. The outgoing network packet traffic is distributed according to the current load (computed relative to the speed) on each network interface slave. Incoming traffic is received by one currently designated slave network interface. If this receiving slave fails, another slave takes over the MAC address of the failed receiving slave.
- Adaptive load balancing (balance-alb): Includes balance-tlb plus receive load balancing (rlb) for IPV4 traffic, and does not require any special network switch support. The receive load balancing is achieved by ARP negotiation. The bonding driver intercepts the ARP Replies sent by the local system on their way out and overwrites the source hardware address with the unique hardware address of one of the NIC slaves in the single logical bonded interface such that different network-peers use different MAC addresses for their network packet traffic.
![]() Related Files
Related Files
1
2
3
/etc/network/interfaces
/etc/hosts
/etc/resolv.conf
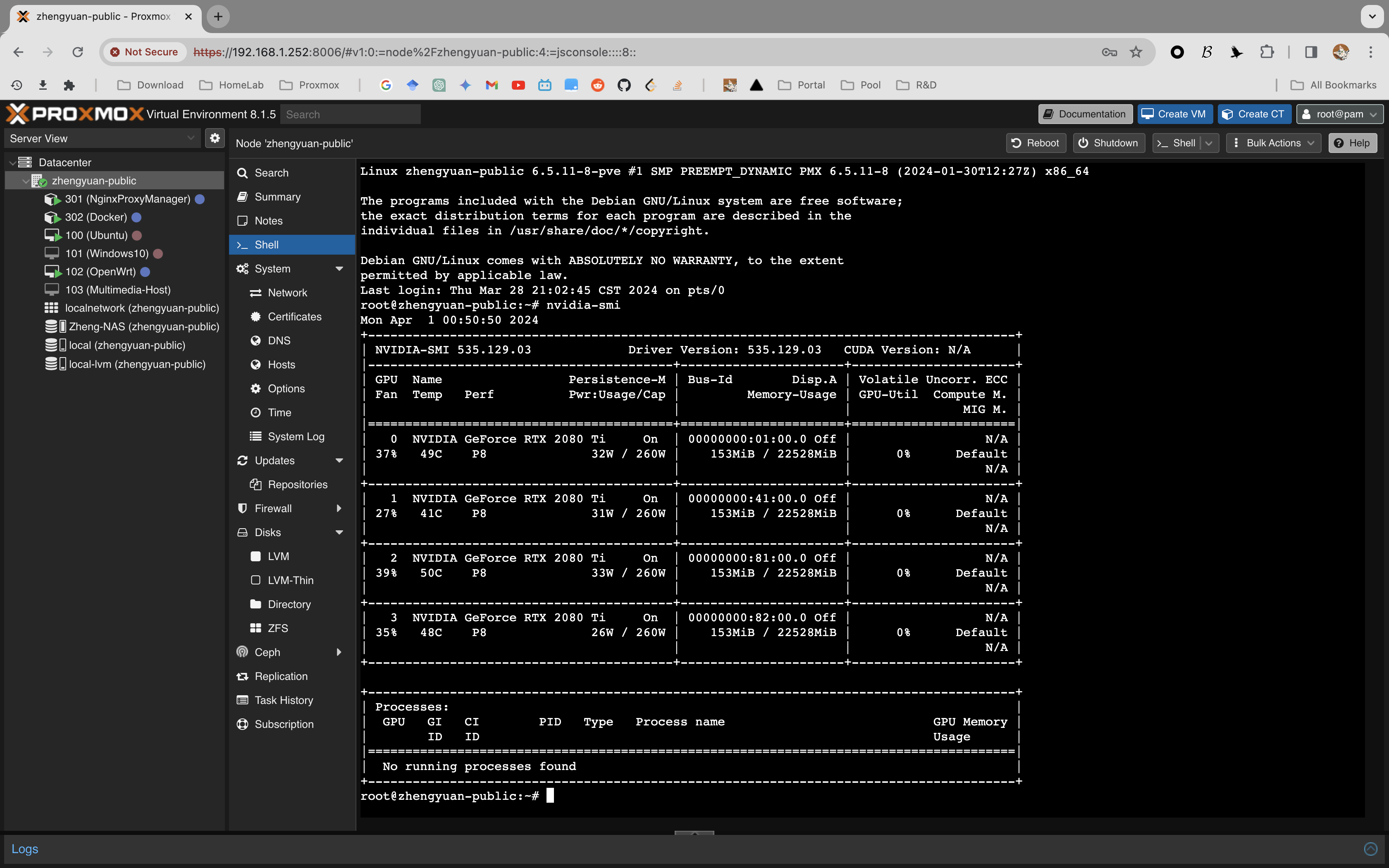
GPU Passthrough
Reference
PCI Passthrough (Proxmox Documentation) ![]()
The Ultimate Beginner’s Guide to GPU Passthrough (Reddit) ![]()
AMD/NVIDIA GPU Passthrough in Windows 11 - Proxmox Guide (YouTube Video) ![]()
Step 1 - Enable IOMMU
IOMMU = (Input/Output Memory Management Unit)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#--- Check if IOMMU is enabled ---#
$ dmesg | grep -e DMAR -e IOMMU
[ 1.406181] pci 0000:c0:00.2: AMD-Vi: IOMMU performance counters supported
[ 1.413634] pci 0000:80:00.2: AMD-Vi: IOMMU performance counters supported
[ 1.424222] pci 0000:40:00.2: AMD-Vi: IOMMU performance counters supported
[ 1.435644] pci 0000:00:00.2: AMD-Vi: IOMMU performance counters supported
[ 1.446665] pci 0000:c0:00.2: AMD-Vi: Found IOMMU cap 0x40
[ 1.446678] pci 0000:80:00.2: AMD-Vi: Found IOMMU cap 0x40
[ 1.446684] pci 0000:40:00.2: AMD-Vi: Found IOMMU cap 0x40
[ 1.446689] pci 0000:00:00.2: AMD-Vi: Found IOMMU cap 0x40
[ 1.447894] perf/amd_iommu: Detected AMD IOMMU #0 (2 banks, 4 counters/bank).
[ 1.447905] perf/amd_iommu: Detected AMD IOMMU #1 (2 banks, 4 counters/bank).
[ 1.447916] perf/amd_iommu: Detected AMD IOMMU #2 (2 banks, 4 counters/bank).
[ 1.447927] perf/amd_iommu: Detected AMD IOMMU #3 (2 banks, 4 counters/bank).
# If you see any output with the words "DMAR" or "IOMMU," then it's likely that
# your system has IOMMU enabled.
$ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-6.2.16-3-pve root=/dev/mapper/pve-root ro quiet amd_iommu=on
# If you find iommu=on in the output, it confirms that IOMMU is enabled.
1
2
3
4
5
6
7
8
9
10
11
#--- Modify GRUB ---#
$ nano /etc/default/grub
# Change the following line
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on" # ===> If you are using Intel CPUs
GRUB_CMDLINE_LINUX_DEFAULT="quiet amd_iommu=on" # ===> If you are using AMD CPUs
# Update grub
$ update-grub
Step 2 - VFIO Modules
1
2
3
4
5
6
7
8
#--- Add modules ---#
$ nano /etc/modules
# Add the following lines
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
Step 3: IOMMU Interrupt Remapping
1
2
3
$ echo "options vfio_iommu_type1 allow_unsafe_interrupts=1" > \
/etc/modprobe.d/iommu_unsafe_interrupts.conf
$ echo "options kvm ignore_msrs=1" > /etc/modprobe.d/kvm.conf
Step 4: Blacklisting Drivers
1
2
3
4
5
6
# Nouveau [noo-voh] adj. newly or recently created, developed, or come to prominence
$ echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
# AMD Drivers
$ echo "blacklist radeon" >> /etc/modprobe.d/blacklist.conf
# Nvidia Drivers
$ echo "blacklist nvidia" >> /etc/modprobe.d/blacklist.conf
*Reboot the system after this step.
Step 5: Adding GPU to VFIO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#--- Find your GPUs ---#\
$ lspci | grep NVIDIA
# Take a note for all IDs
01:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti Rev. A]
01:00.1 Audio device: NVIDIA Corporation TU102 High Definition Audio Controller
01:00.2 USB controller: NVIDIA Corporation TU102 USB 3.1 Host Controller
01:00.3 Serial bus controller: NVIDIA Corporation TU102 USB Type-C UCSI Controller
41:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti Rev. A]
41:00.1 Audio device: NVIDIA Corporation TU102 High Definition Audio Controller
41:00.2 USB controller: NVIDIA Corporation TU102 USB 3.1 Host Controller
41:00.3 Serial bus controller: NVIDIA Corporation TU102 USB Type-C UCSI Controller
81:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti Rev. A]
81:00.1 Audio device: NVIDIA Corporation TU102 High Definition Audio Controller
81:00.2 USB controller: NVIDIA Corporation TU102 USB 3.1 Host Controller
81:00.3 Serial bus controller: NVIDIA Corporation TU102 USB Type-C UCSI Controller
82:00.0 VGA compatible controller: NVIDIA Corporation TU102 [GeForce RTX 2080 Ti Rev. A]
82:00.1 Audio device: NVIDIA Corporation TU102 High Definition Audio Controller
82:00.2 USB controller: NVIDIA Corporation TU102 USB 3.1 Host Controller
82:00.3 Serial bus controller: NVIDIA Corporation TU102 USB Type-C UCSI Controller
# IDs for this system are 01:00, 41:00, 81:00, and 82:00.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#--- Find GPU card's Vendor IDs ---#
$ lspci -n -s 01:00
01:00.0 0300: 10de:1e07 (rev a1)
01:00.1 0403: 10de:10f7 (rev a1)
01:00.2 0c03: 10de:1ad6 (rev a1)
01:00.3 0c80: 10de:1ad7 (rev a1)
$ lspci -n -s 41:00
01:00.0 0300: 10de:1e07 (rev a1)
01:00.1 0403: 10de:10f7 (rev a1)
01:00.2 0c03: 10de:1ad6 (rev a1)
01:00.3 0c80: 10de:1ad7 (rev a1)
# Got the same result because I had 4 identical GPU
# Change ids to your own ids
$ echo "options vfio-pci ids=10de:1e07, 10de:10f7, 10de:1ad6, 10de:1ad7, disable_vga=1">\
/etc/modprobe.d/vfio.conf
# Update initramfs
$ update-initramfs -u
# Reboot the system
Step6: Create VM
System Settings
- Graphic Card:
Default - Machine:
q35 - BIOS:
OVMF(UEFI) - SCSI Controller:
VirtIO SCSI
Disk Settings
Additional tips
Ubuntu
NVIDIA Driver
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#--- Remove Old Drivers ---#
$ sudo apt update
$ sudo apt remove --purge nvidia-*
$ sudo apt autoremove --purge
$ sudo apt clean
$ sudo reboot
# Reboot can be necessary before reinstall the driver
#--- Install New Drivers ---#
$ sudo apt search nvidia-driver
# Find available versions
$ sudo apt install nvidia-driver-535
# Might need to set a secure boot password or disable secure boot if necessary
$ sudo reboot
VNC
1
2
3
#--- Install Dependencies ---#
$ sudo apt install vino
$ sudo apt install dconf-editor
*Navigate to /org/gnome/desktop/remote-access with dconf-editor and disable require-encryption
Windows
Additional CPU Flags
1
2
3
4
5
6
7
# /etc/pve/qemu-server/<vmid>.conf
$ nano /etc/pve/qemu-server/101.conf
# Add the following lines at the end of the file
machine: q35
cpu: host,hidden=1,flags=+pcid
args: -cpu 'host,+kvm_pv_unhalt,+kvm_pv_eoi,hv_vendor_id=NV43FIX,kvm=off'
*The final config file will update automatically after booting the VM
Benchmark
Benchmark using pytorch-gpu-benchmark with default model (resnet50)
| VM Specification | |
|---|---|
| OS | Ubuntu 22.04.3 LTS |
| CPU | 1 Socket 96 Cores |
| RAM | 200 GB |
| Disk | VirtIO SCSI (Cache Mode: None) |
| GPU | [Gigabyte-NVIDIA-2080Ti-22GB-300A]x 4 |
| Software | Version |
|---|---|
| NVIDIA Driver | 535.86.05 |
| CUDA | 12.2 |
| torch | 2.0.1 |
| torchaudio | 2.0.2 |
| torchvision | 0.15.2 |
ResNet-50 FP16 Benchmark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
$ python3 main.py --num_gpus 4 --use_fp16 --batch_size 450
OS: Linux, 6.2.0-26-generic
Device-name: Ubuntu-VM
4 GPU(s) used for benchmark:
0: NVIDIA GeForce RTX 2080 Ti
1: NVIDIA GeForce RTX 2080 Ti
2: NVIDIA GeForce RTX 2080 Ti
3: NVIDIA GeForce RTX 2080 Ti
Nvidia GPU driver version: 535.86.05
Available GPUs on device: 4
Cuda-version: 11.7
Cudnn-version: 8500
Python-version: 3.11.4
PyTorch-version: 2.0.1+cu117
CPU: AMD EPYC 7642 48-Core Processor
Model: resnet50
Global train batch size: 1800
Local train batch size: 450
Global evaluation batch size: 1800
Local evaluation batch size: 450
Distribution Mode: Distributed Data Parallel
Process group backend: nccl
Optimizer: SGD
Precision: half
Log file: 4_NVIDIAGeForceRTX2080Ti_resnet50_450_lr0001.txt
Training data: Synthetic data
Initial learning rate: 0.001
Learning rate decay step: 30
Used data augmentation: True
Checkpoint folder: /home/foo/Documents/pytorch-benchmarks-main\
/model_checkpoints/4_NVIDIAGeForceRTX2080Ti_resnet50_450_lr0001
Number of workers: 16
Warm up steps: 10
Benchmark start : 2023/07/26 18:14:27
Epoch 1
Epoch [1 / 10], Step [10 / 56], Loss: 7.0391, Images per second: 771.2
Epoch [1 / 10], Step [20 / 56], Loss: 7.0039, Images per second: 2210.7
Epoch [1 / 10], Step [30 / 56], Loss: 6.9727, Images per second: 2204.7
Epoch [1 / 10], Step [40 / 56], Loss: 6.9531, Images per second: 2199.5
Epoch [1 / 10], Step [50 / 56], Loss: 6.9844, Images per second: 2196.0
Epoch [1 / 10], Step [56 / 56], Loss: 6.9570
Training epoch finished within 1 minutes and 3 seconds.
Epoch 2
Epoch [2 / 10], Step [10 / 56], Loss: 6.9570, Images per second: 803.6
Epoch [2 / 10], Step [20 / 56], Loss: 7.0000, Images per second: 2189.1
Epoch [2 / 10], Step [30 / 56], Loss: 6.9609, Images per second: 2175.1
Epoch [2 / 10], Step [40 / 56], Loss: 7.0117, Images per second: 2166.0
Epoch [2 / 10], Step [50 / 56], Loss: 7.0000, Images per second: 2163.5
Epoch [2 / 10], Step [56 / 56], Loss: 6.9922
Training epoch finished within 56 seconds.
Epoch 3
Epoch [3 / 10], Step [10 / 56], Loss: 6.9883, Images per second: 794.1
Epoch [3 / 10], Step [20 / 56], Loss: 6.9766, Images per second: 2168.9
Epoch [3 / 10], Step [30 / 56], Loss: 6.9219, Images per second: 2160.4
Epoch [3 / 10], Step [40 / 56], Loss: 6.9961, Images per second: 2151.8
Epoch [3 / 10], Step [50 / 56], Loss: 6.9844, Images per second: 2142.0
Epoch [3 / 10], Step [56 / 56], Loss: 7.0000
Training epoch finished within 56 seconds.
Epoch 4
Epoch [4 / 10], Step [10 / 56], Loss: 6.9883, Images per second: 788.4
Epoch [4 / 10], Step [20 / 56], Loss: 6.9648, Images per second: 2159.9
Epoch [4 / 10], Step [30 / 56], Loss: 6.9609, Images per second: 2146.7
Epoch [4 / 10], Step [40 / 56], Loss: 6.9844, Images per second: 2137.8
Epoch [4 / 10], Step [50 / 56], Loss: 6.9883, Images per second: 2128.0
Epoch [4 / 10], Step [56 / 56], Loss: 6.9609
Training epoch finished within 56 seconds.
Epoch 5
Epoch [5 / 10], Step [10 / 56], Loss: 6.9883, Images per second: 787.1
Epoch [5 / 10], Step [20 / 56], Loss: 6.9453, Images per second: 2156.1
Epoch [5 / 10], Step [30 / 56], Loss: 6.9492, Images per second: 2139.3
Epoch [5 / 10], Step [40 / 56], Loss: 6.9648, Images per second: 2126.1
Epoch [5 / 10], Step [50 / 56], Loss: 6.9609, Images per second: 2122.5
Epoch [5 / 10], Step [56 / 56], Loss: 7.0000
Training epoch finished within 57 seconds.
Epoch 6
Epoch [6 / 10], Step [10 / 56], Loss: 6.9883, Images per second: 805.2
Epoch [6 / 10], Step [20 / 56], Loss: 6.9609, Images per second: 2147.5
Epoch [6 / 10], Step [30 / 56], Loss: 6.9883, Images per second: 2132.7
Epoch [6 / 10], Step [40 / 56], Loss: 6.9805, Images per second: 2120.5
Epoch [6 / 10], Step [50 / 56], Loss: 6.9727, Images per second: 2115.7
Epoch [6 / 10], Step [56 / 56], Loss: 6.9766
Training epoch finished within 56 seconds.
Epoch 7
Epoch [7 / 10], Step [10 / 56], Loss: 7.0273, Images per second: 794.4
Epoch [7 / 10], Step [20 / 56], Loss: 7.0078, Images per second: 2144.1
Epoch [7 / 10], Step [30 / 56], Loss: 6.9805, Images per second: 2130.8
Epoch [7 / 10], Step [40 / 56], Loss: 6.9961, Images per second: 2116.6
Epoch [7 / 10], Step [50 / 56], Loss: 7.0195, Images per second: 2112.0
Epoch [7 / 10], Step [56 / 56], Loss: 7.0039
Training epoch finished within 57 seconds.
Epoch 8
Epoch [8 / 10], Step [10 / 56], Loss: 7.0156, Images per second: 810.8
Epoch [8 / 10], Step [20 / 56], Loss: 6.9805, Images per second: 2141.9
Epoch [8 / 10], Step [30 / 56], Loss: 6.9961, Images per second: 2125.9
Epoch [8 / 10], Step [40 / 56], Loss: 6.9844, Images per second: 2112.2
Epoch [8 / 10], Step [50 / 56], Loss: 6.9766, Images per second: 2108.4
Epoch [8 / 10], Step [56 / 56], Loss: 6.9922
Training epoch finished within 56 seconds.
Epoch 9
Epoch [9 / 10], Step [10 / 56], Loss: 6.9961, Images per second: 818.9
Epoch [9 / 10], Step [20 / 56], Loss: 7.0391, Images per second: 2138.7
Epoch [9 / 10], Step [30 / 56], Loss: 6.9922, Images per second: 2126.8
Epoch [9 / 10], Step [40 / 56], Loss: 6.9570, Images per second: 2114.1
Epoch [9 / 10], Step [50 / 56], Loss: 7.0156, Images per second: 2108.8
Epoch [9 / 10], Step [56 / 56], Loss: 6.9766
Training epoch finished within 56 seconds.
Epoch 10
Epoch [10 / 10], Step [10 / 56], Loss: 6.9805, Images per second: 803.2
Epoch [10 / 10], Step [20 / 56], Loss: 6.9766, Images per second: 2135.6
Epoch [10 / 10], Step [30 / 56], Loss: 7.0078, Images per second: 2122.3
Epoch [10 / 10], Step [40 / 56], Loss: 6.9961, Images per second: 2115.6
Epoch [10 / 10], Step [50 / 56], Loss: 6.9727, Images per second: 2101.7
Epoch [10 / 10], Step [56 / 56], Loss: 6.9961
Training epoch finished within 56 seconds.
Benchmark end: 2023/07/26 18:23:55
I tried different batch sizes to fully utilize VRAM and 450 seemed fine (VRAM usage at[21.6/22]=98.18%)
The benchmark took 568 seconds to finish and about 147 GB of RAM was used.
ResNet-50 FP32 Benchmark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
$ python3 main.py --num_gpus 4 --batch_size 250
OS: Linux, 6.2.0-26-generic
Device-name: Ubuntu-VM
4 GPU(s) used for benchmark:
0: NVIDIA GeForce RTX 2080 Ti
1: NVIDIA GeForce RTX 2080 Ti
2: NVIDIA GeForce RTX 2080 Ti
3: NVIDIA GeForce RTX 2080 Ti
Nvidia GPU driver version: 535.86.05
Available GPUs on device: 4
Cuda-version: 11.7
Cudnn-version: 8500
Python-version: 3.11.4
PyTorch-version: 2.0.1+cu117
CPU: AMD EPYC 7642 48-Core Processor
Model: resnet50
Global train batch size: 1000
Local train batch size: 250
Global evaluation batch size: 1000
Local evaluation batch size: 250
Distribution Mode: Distributed Data Parallel
Process group backend: nccl
Optimizer: SGD
Precision: float
Log file: 4_NVIDIAGeForceRTX2080Ti_resnet50_250_lr0001.txt
Training data: Synthetic data
Initial learning rate: 0.001
Learning rate decay step: 30
Used data augmentation: True
Checkpoint folder: /home/foo/Documents/pytorch-benchmarks-main\
/model_checkpoints/4_NVIDIAGeForceRTX2080Ti_resnet50_250_lr0001
Number of workers: 16
Warm up steps: 10
Benchmark start : 2023/07/26 20:19:28
Epoch 1
Epoch [1 / 10], Step [10 / 100], Loss: 7.0617, Images per second: 528.9
Epoch [1 / 10], Step [20 / 100], Loss: 7.0085, Images per second: 1066.2
Epoch [1 / 10], Step [30 / 100], Loss: 6.9852, Images per second: 1061.7
Epoch [1 / 10], Step [40 / 100], Loss: 6.9623, Images per second: 1058.0
Epoch [1 / 10], Step [50 / 100], Loss: 6.9462, Images per second: 1055.3
Epoch [1 / 10], Step [60 / 100], Loss: 6.9895, Images per second: 1053.4
Epoch [1 / 10], Step [70 / 100], Loss: 6.9272, Images per second: 1051.1
Epoch [1 / 10], Step [80 / 100], Loss: 6.9335, Images per second: 1048.8
Epoch [1 / 10], Step [90 / 100], Loss: 6.9348, Images per second: 1046.3
Epoch [1 / 10], Step [100 / 100], Loss: 6.9647
Training epoch finished within 1 minutes and 47 seconds.
Epoch 2
Epoch [2 / 10], Step [10 / 100], Loss: 6.9869, Images per second: 383.8
Epoch [2 / 10], Step [20 / 100], Loss: 6.9779, Images per second: 1047.0
Epoch [2 / 10], Step [30 / 100], Loss: 6.9534, Images per second: 1044.4
Epoch [2 / 10], Step [40 / 100], Loss: 7.0300, Images per second: 1041.4
Epoch [2 / 10], Step [50 / 100], Loss: 7.0033, Images per second: 1036.4
Epoch [2 / 10], Step [60 / 100], Loss: 6.9550, Images per second: 1032.6
Epoch [2 / 10], Step [70 / 100], Loss: 6.9800, Images per second: 1030.2
Epoch [2 / 10], Step [80 / 100], Loss: 6.9632, Images per second: 1027.3
Epoch [2 / 10], Step [90 / 100], Loss: 6.9934, Images per second: 1026.1
Epoch [2 / 10], Step [100 / 100], Loss: 6.9995
Training epoch finished within 1 minutes and 43 seconds.
Epoch 3
Epoch [3 / 10], Step [10 / 100], Loss: 6.9514, Images per second: 386.8
Epoch [3 / 10], Step [20 / 100], Loss: 6.9584, Images per second: 1036.0
Epoch [3 / 10], Step [30 / 100], Loss: 6.9304, Images per second: 1028.5
Epoch [3 / 10], Step [40 / 100], Loss: 6.9792, Images per second: 1023.9
Epoch [3 / 10], Step [50 / 100], Loss: 6.9403, Images per second: 1020.4
Epoch [3 / 10], Step [60 / 100], Loss: 6.9888, Images per second: 1018.2
Epoch [3 / 10], Step [70 / 100], Loss: 6.9715, Images per second: 1017.6
Epoch [3 / 10], Step [80 / 100], Loss: 6.9615, Images per second: 1012.7
Epoch [3 / 10], Step [90 / 100], Loss: 6.9275, Images per second: 1014.6
Epoch [3 / 10], Step [100 / 100], Loss: 6.9781
Training epoch finished within 1 minutes and 45 seconds.
Epoch 4
Epoch [4 / 10], Step [10 / 100], Loss: 6.9462, Images per second: 386.1
Epoch [4 / 10], Step [20 / 100], Loss: 6.9678, Images per second: 1028.2
Epoch [4 / 10], Step [30 / 100], Loss: 6.9746, Images per second: 1020.9
Epoch [4 / 10], Step [40 / 100], Loss: 6.9846, Images per second: 1018.0
Epoch [4 / 10], Step [50 / 100], Loss: 6.9702, Images per second: 1015.3
Epoch [4 / 10], Step [60 / 100], Loss: 6.9563, Images per second: 1015.1
Epoch [4 / 10], Step [70 / 100], Loss: 6.9801, Images per second: 1010.5
Epoch [4 / 10], Step [80 / 100], Loss: 6.9407, Images per second: 1011.5
Epoch [4 / 10], Step [90 / 100], Loss: 6.9285, Images per second: 1009.2
Epoch [4 / 10], Step [100 / 100], Loss: 6.9624
Training epoch finished within 1 minutes and 45 seconds.
Epoch 5
Epoch [5 / 10], Step [10 / 100], Loss: 6.9572, Images per second: 384.5
Epoch [5 / 10], Step [20 / 100], Loss: 6.9814, Images per second: 1024.4
Epoch [5 / 10], Step [30 / 100], Loss: 6.9617, Images per second: 1016.8
Epoch [5 / 10], Step [40 / 100], Loss: 6.9745, Images per second: 1012.2
Epoch [5 / 10], Step [50 / 100], Loss: 6.9796, Images per second: 1012.7
Epoch [5 / 10], Step [60 / 100], Loss: 7.0011, Images per second: 1010.0
Epoch [5 / 10], Step [70 / 100], Loss: 7.0131, Images per second: 1007.0
Epoch [5 / 10], Step [80 / 100], Loss: 6.9857, Images per second: 1008.8
Epoch [5 / 10], Step [90 / 100], Loss: 6.9562, Images per second: 1007.5
Epoch [5 / 10], Step [100 / 100], Loss: 6.9534
Training epoch finished within 1 minutes and 45 seconds.
Epoch 6
Epoch [6 / 10], Step [10 / 100], Loss: 6.9592, Images per second: 383.5
Epoch [6 / 10], Step [20 / 100], Loss: 6.9643, Images per second: 1023.8
Epoch [6 / 10], Step [30 / 100], Loss: 6.9408, Images per second: 1015.0
Epoch [6 / 10], Step [40 / 100], Loss: 6.9969, Images per second: 1011.3
Epoch [6 / 10], Step [50 / 100], Loss: 6.9519, Images per second: 1009.4
Epoch [6 / 10], Step [60 / 100], Loss: 6.9442, Images per second: 1009.5
Epoch [6 / 10], Step [70 / 100], Loss: 7.0022, Images per second: 1009.0
Epoch [6 / 10], Step [80 / 100], Loss: 6.9650, Images per second: 1008.2
Epoch [6 / 10], Step [90 / 100], Loss: 6.9554, Images per second: 1007.2
Epoch [6 / 10], Step [100 / 100], Loss: 6.9972
Training epoch finished within 1 minutes and 46 seconds.
Epoch 7
Epoch [7 / 10], Step [10 / 100], Loss: 6.9187, Images per second: 376.1
Epoch [7 / 10], Step [20 / 100], Loss: 6.9507, Images per second: 1025.3
Epoch [7 / 10], Step [30 / 100], Loss: 6.9749, Images per second: 1015.6
Epoch [7 / 10], Step [40 / 100], Loss: 6.9885, Images per second: 1011.6
Epoch [7 / 10], Step [50 / 100], Loss: 6.9592, Images per second: 1011.4
Epoch [7 / 10], Step [60 / 100], Loss: 6.9692, Images per second: 1010.7
Epoch [7 / 10], Step [70 / 100], Loss: 6.9642, Images per second: 1008.4
Epoch [7 / 10], Step [80 / 100], Loss: 6.9296, Images per second: 1008.0
Epoch [7 / 10], Step [90 / 100], Loss: 6.9669, Images per second: 1007.7
Epoch [7 / 10], Step [100 / 100], Loss: 6.9564
Training epoch finished within 1 minutes and 45 seconds.
Epoch 8
Epoch [8 / 10], Step [10 / 100], Loss: 6.9623, Images per second: 376.1
Epoch [8 / 10], Step [20 / 100], Loss: 6.9965, Images per second: 1023.7
Epoch [8 / 10], Step [30 / 100], Loss: 6.9735, Images per second: 1014.6
Epoch [8 / 10], Step [40 / 100], Loss: 6.9743, Images per second: 1011.9
Epoch [8 / 10], Step [50 / 100], Loss: 6.9756, Images per second: 1008.8
Epoch [8 / 10], Step [60 / 100], Loss: 6.9497, Images per second: 1009.0
Epoch [8 / 10], Step [70 / 100], Loss: 6.9890, Images per second: 1009.3
Epoch [8 / 10], Step [80 / 100], Loss: 6.9741, Images per second: 1007.4
Epoch [8 / 10], Step [90 / 100], Loss: 6.9257, Images per second: 1006.7
Epoch [8 / 10], Step [100 / 100], Loss: 6.9709
Training epoch finished within 1 minutes and 46 seconds.
Epoch 9
Epoch [9 / 10], Step [10 / 100], Loss: 6.9802, Images per second: 374.6
Epoch [9 / 10], Step [20 / 100], Loss: 7.0295, Images per second: 1022.1
Epoch [9 / 10], Step [30 / 100], Loss: 6.9304, Images per second: 1016.3
Epoch [9 / 10], Step [40 / 100], Loss: 6.9575, Images per second: 1012.8
Epoch [9 / 10], Step [50 / 100], Loss: 6.9454, Images per second: 1009.2
Epoch [9 / 10], Step [60 / 100], Loss: 6.9774, Images per second: 1009.9
Epoch [9 / 10], Step [70 / 100], Loss: 6.9958, Images per second: 1009.7
Epoch [9 / 10], Step [80 / 100], Loss: 6.9711, Images per second: 1008.8
Epoch [9 / 10], Step [90 / 100], Loss: 6.9199, Images per second: 1007.7
Epoch [9 / 10], Step [100 / 100], Loss: 6.9748
Training epoch finished within 1 minutes and 46 seconds.
Epoch 10
Epoch [10 / 10], Step [10 / 100], Loss: 6.9681, Images per second: 385.7
Epoch [10 / 10], Step [20 / 100], Loss: 6.9494, Images per second: 1023.1
Epoch [10 / 10], Step [30 / 100], Loss: 6.9762, Images per second: 1015.1
Epoch [10 / 10], Step [40 / 100], Loss: 6.9469, Images per second: 1013.3
Epoch [10 / 10], Step [50 / 100], Loss: 6.9338, Images per second: 1011.7
Epoch [10 / 10], Step [60 / 100], Loss: 7.0021, Images per second: 1009.8
Epoch [10 / 10], Step [70 / 100], Loss: 6.9517, Images per second: 1008.3
Epoch [10 / 10], Step [80 / 100], Loss: 6.9772, Images per second: 1007.9
Epoch [10 / 10], Step [90 / 100], Loss: 7.0099, Images per second: 1006.4
Epoch [10 / 10], Step [100 / 100], Loss: 6.9805
Training epoch finished within 1 minutes and 44 seconds.
Benchmark end: 2023/07/26 20:36:59
With batch size set to 250, the VRAM usage was at[21.9/22]=99.55%. The benchmark took 1051 seconds to finish and about 87 GB of RAM was used.
Gallary